Kubernetes Basics
What is it?
- Kubernetes (K8s) is an open-source container orchestration tool for managing applications on container runtimes like Docker.
- Provides a platform-agnostic, self-healing, and fully automatable framework for hosting containerized applications.
- Uses a collection of controller services hosted on control server(s) to manage worker servers in a server cluster. The application code is held on the worker servers, and the control server controls when, what, and how containers are built on the worker servers.
High-level K8s Architecture
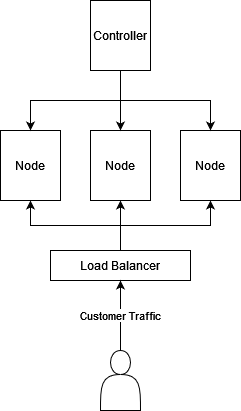
- Kubernetes Documentation at: https://kubernetes.io/docs/home/
- Docker Documentation at: https://docs.docker.com/
Why use it?
- K8s is a tool that allows you to centrally manage container image deployment and updates, define resource usage standards, monitor the health of an application, and maintain control over an environment at-scale when running services on containers.
- If configured correctly, provides high fault-tolerance for your container app.
- it is best use where containers are being used for large apps with multiple microservices requiring High Availability and redundancy.
Alternatives
- K8s is NOT the only solution for managing containers at scale, but it is the most popular. Other solutions include Amazon Elastic Container Service (ECS), Docker Swarm, and OpenShift.
- For containerized small apps on a single server,a more straight-forward service with less focus on distributed services like Docker Compose is the best way to go.
- Amazon Elastic Kubernetes Service (EKS) and Google Kubernetes Engine (GKE) are managed solutions that allow teams to delegate the management of the underlying operating system and hardware to a cloud provider.
A few key SysOps/Deployment Concepts
High Availability
High Availability (HA) is the concept of making your application/service fault-tolerant and redundant, as to prevent downtime in the case of an incident. Examples of incidents that High Availability configurations attempt to solve for are:
- A server is overloaded with requests and users are unable to reach the service.
- A database experiences temporary IO suspension due to a scheduled backup.
- A natural disaster knocks out power in a data center, leaving your servers unresponsive for a period of time.
- A bug causes an application to crash unexpectedly.
Common solutions for providing High Availability include:
- hosting servers in multiple data centers across multiple regions (ideally, at least 3).
- backing up data to storage that is isolated from the data store being backed-up.
- Automate health-checks to fail-over between servers if a server is experiencing issues
- Disaster planning, have back-up servers on standby
Scalability
- Providing Scalability in the context of a application is the process of building a system to efficiently adjust for variance in compute or traffic load. When the amount of people shopping on a site doubles for Cyber Monday, an online store and its components should be able to adjust on-the-fly to handle the load
- To allow your application/service to be scalable, you can:
- Monitor the health/resource usage of application servers and write code to create new virtual machines to meet new requirements. Have your automation delete these new virtual machines when the load is back to normal.
- Use one of the many solutions provided by cloud providers, like AWS EC2 AutoScaling, to create new cloud servers to match the compute capacity needed, delete these servers when the load decreases.
- Use Load Balancers to direct traffic to instances using round-robin or other traffic direction method to allow traffic to reach new servers on-the-fly
- Applications can scale horizontally or vertically
- Horizontal scaling: Create new instances of the application server of the same/similar size. Ex: a server uses 90% of its CPU capacity, a new virtual server is created with the same CPU capacity and requests are load-balanced between the two servers.
- Vertical scaling: Create a larger version of the application server. Ex: a server uses 90% of its CPU capacity, a new instance is created with a higher-end CPU and traffic is redirected.
Okay, finally back to Kubernetes
Kubernetes Components
Key Terms:
- Node: A single virtual/physical server/instance
- Control Plane: the server(s)/instance(s) that command and control the worker nodes
- Pod: One or more containers on a node, smallest component in K8s
- Load Balancer: A physical or virtual networking component that directs traffic between nodes.
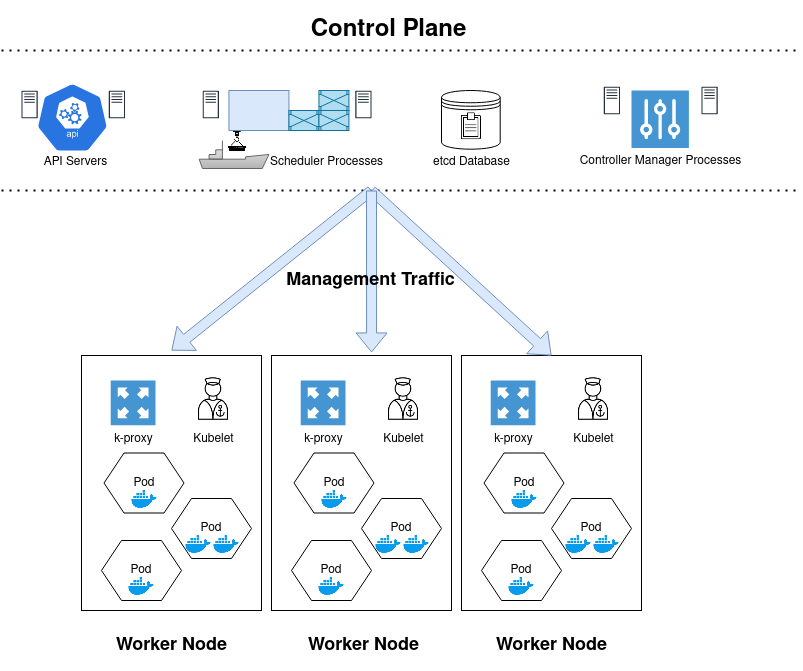
Nodes
- Nodes are individual physical/virtual servers that contain a number of components to send/receive instructions from the control node (see Control Plane for details) and host the containers running your service. Node components include:
- Pod: the smallest unit in the K8s architecture, pods contain one or more containers that are tightly coupled to serve a single function. Multiple container pods might be implemented where a separate container is acting as a networking proxy, acting as a helper or sidecar container to handle logging, monitoring.
- kubelet: the K8s agent running on each node that communicates back to the control plane.
- kube-proxy: A network proxy that maintains network rules permitting traffic from the node to other parts of the cluster, or outside of the cluster.
Control Plane
- The Control Plane is a collection of cluster management services that run across multiple servers. These services track the health of worker nodes, keep inventory of what containers are deployed and where, track and update what container images are being used, and provide an API interface for administrators to manage the cluster.
- Some Control Plane Components Are:
- API Server:
- Exposes the K8s API, usually with the
kube-apiserverimplementation. This implementation scales to match load needs by deploying new instances to handle API requests (horizontal scaling)
- Exposes the K8s API, usually with the
- Cloud Controller Manager (optional if running locally):
- Controls the cloud infrastructure for your specific cloud provider’s infrastructure.
- Service Controller: Creates load balancers
- Route Controller: manages routes within the cloud provider’s infrastructure
- Node controller: Checks to see if an unresponsive node was terminated by the cloud provider
- Controller Manager:
kube-controller-managerruns each of the controller processes as a single binary. These controller processes include:- Node controller: Checks on the status of nodes and respond when a node goes down
- Replication controller: maintains the correct number of pods.
- Endpoints controller: joins services to pods by populating an Endpoints object
- Service account and Token controllers; Creates the default accounts and API access tokens for new namespaces
- Scheduler: kube-scheduler watches for newly created pods that have not been assigned a node, and selects a node for them to run on based on resource requirements, hardware/software policy constraints, label-based eligibility (affinity and anti-affinity), deadlines and workload interference.
- etcd: A highly-available (distributed across servers) key-value store for all persistent cluster data. Periodic back-ups are recommended here.
- API Server:
In Practice
- Kubernetes at-scale can require a significant amount of engineering resources and can become complex as an application grows and the number of microservices increases. Running self-managed K8s in production should be restricted to companies with experienced staff and the people-power to manage it securely.
- If a team runs a service or application running across multiple cloud providers, A service like Amazon’s Elastic Kubernetes Service (EKS) may be a better alternative. EKS provides high availability and redundancy by default, with three control nodes across three availability zones (data centers) by default, but can still be controlled via the K8s api using kube-ctl.
- If a team runs an AWS-native application, a managed service like Amazon ECS on EC2 or Fargate can be employed to more easily integrate with AWS-native services.
Additional Resources for Kubernetes Practice:
- K3s: a minimal Kubernetes install with the control plane in a single binary: https://k3s.io/
- OpenShift: A GUI-based developer-oriented Kubernetes experience. Red Hat provides a learning sandbox: https://www.redhat.com/en/technologies/cloud-computing/openshift/try-it?intcmp=7013a000002D1gVAAS
adbddf6 @ 2021-10-18